Interoperability
New features to round out 2024!
Interested in FHIR, OAuth, webhooks, or support portals? Here’s a round up of the new features we intend to release before the end of the year.
Here's a sneak peek of what's coming up - if these features are of interest to you, don't forget to provide some feedback!
Some of our recent releases have already included some behind-the-scenes infrastructure work to improve performance and reliability. Now it’s time to do the customer-facing features — and we’d love to hear from you if you have any feedback.
Our immediate queries are designed to be small and fast, and are given queue priority in order to support real-time use cases. However, due to using Web PubSub in their implementation, immediates have been limited to 1MB of data. This has worked for many use cases to date, but we know there are real-time requirements for larger amounts of data, such as writing back clinically urgent reports, which we’re now looking to tackle.
Development has already begun on evolving immediate queries to leverage the Claim-Check pattern, which will remove the 1MB limit. We'll be experimenting with where to set the upper limit so that we strike a balance between performance and accommodating lots of use cases, and we'll make sure we will update the docs appropriately.
This change will apply to both the SQL Passthrough API and the FHIR API, which currently uses immediate queries under the hood.
For simplicity’s sake, we’re calling this project multithreading, even though what we’re implementing isn’t technically multithreading. Either way, the result is the same: we’re working on splitting out Halo Link’s different functionalities so they can run in parallel.
The goal here is to avoid the situation where one integrator’s queries could affect the performance of another integrator’s. So far, this hasn’t been an issue. Even at practices that run multiple integrations via Halo, we haven’t seen any cross-integrator impact. However, we’re conscious that the more integrators we onboard, the more likely this becomes. So we’re looking to get ahead of the situation by starting development on a solution now.
It’s also something we’ve required of ourselves for implementing bigger immediate queries — adding multithreading helps mitigate the risk of bigger immediates clogging up the queue for other integrators.
Another concern we’ve been working on for a while is how to make Halo affordable for those integrators with really chatty use cases. The ones who need to be polling every practice every minute or so, or are constantly reading and writing appointments. This gets expensive quickly — every query costs some fraction of a cent, and that adds up when you’re doing tens of thousands of queries a day.
We’ve gone through a few iterations for how to solve this, and bounced our ideas around with several current integrators (thank you for the feedback!), and we think we’ve found an approach that should work while maintaining our strict security model.
Registered queries. That’s the name of the project we will soon be embarking on.
This will allow integrators to register a set number of queries they want to run repeatedly, including how frequently and for how long. Halo Link will then run the queries for them on the given schedule and upload the result each time to Halo Cloud, so integrators can fetch the latest results directly from the cloud like with an async query.
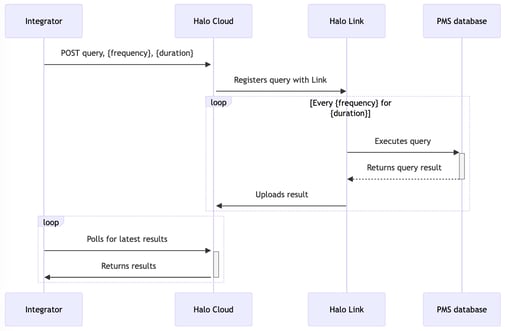
This allows integrators to poll the database at the frequency they need, but reduces the overhead by massively decreasing the number of queries being sent down to Halo Link, which is the most expensive part of sending a query.
We also have some future plans to enhance this functionality with webhooks, to remove the need for polling altogether.
These features will be rolling out pretty rapidly over the next few months, and we’ll be sure to share more info as they do. If you’d like to know more about any of the features we have coming down the line, or would like to talk about how these improvements will fit your use case, please feel free to reach out to support@haloconnect.io.
Interested in FHIR, OAuth, webhooks, or support portals? Here’s a round up of the new features we intend to release before the end of the year.
We've been busy! Here's a quick overview of the upcoming improvements across FHIR and security, plus three new features...
Whether you handle patient transfers or need snapshots of patient health records, our new Patient Summary feature is a great way to get the big...